Comparing July Candidate Support in the 2020 Democratic Primary: Building Support Rankings
By Zachery Crowell (@zachacrowell)
In an unwieldy field with upwards of 25 candidates, asking survey respondents to choose a single candidate greatly limits our understanding voters’ preferences. This is especially true early in the race when voters are actively considering several candidates. Instead, what could one infer if surveys asked voters to rank the candidate field rather than merely ask for a top choice? For example, would candidates like Senators Kamala Harris and Elizabeth Warren float to the top? Or would former Vice President Joe Biden appear even more dominant when taking into account ranked preferences?
In the remaining sections, I first describe the data and methods. Then, I look at what ranked preferences can reveal about lane theory, what predicts candidate support, and finally potential proxies for candidate ranks like “net considering”.
Data
Immediately before and after the first Democratic debate, Data for Progress and YouGov Blue fielded a survey asking respondents which candidates they were considering and not considering voting for in the Democratic primary. Furthermore, a followup question asked respondents to rank candidates they were considering in order of preference. Based on the responses to the set of considering/not considering/rank questions, we can infer a lot about relative candidate preferences among the Democratic electorate. In fact, we can build individual candidate rankings for each respondent using a combination of a) direct candidate preferences where they exist and b) imputed candidate support scores.
Methods
Combining the set of considering questions tells us that the median respondent is actively considering four candidates and has ruled out four candidates. In other words, on average we know respondents’ four favorite and four least-favorite candidates. We also know, then, that the 14 remaining candidates should fall somewhere between considering and not considering. For these 14 we could then order based on an imputed candidate score. For example, even though someone may have ranked Sanders first and Biden last, we can make an educated guess that they’re more likely to prefer Warren over Delany based on the answers they’ve given to other questions, like should we tax the rich.
Thus we can build a general procedure to build preference ranks for each individual:
Use considering/ranked and not-considering where we have it.
Temporarily put everyone else in the middle.
Build support models on these incomplete ranks.
Fill in the unranked scores.
Adjust the scores so imputed ranks are consistent with the original ranks. (e.g. someone who ranked 4 candidates can’t have any imputed candidates scores below 4.)
To illustrate, we end up with a final support that looks like this:

We can also see how the final ranks relate to their first stage counterparts and confirm that almost none of the imputation is happening to respondents who indicated they were either considering Harris or had ruled her out.
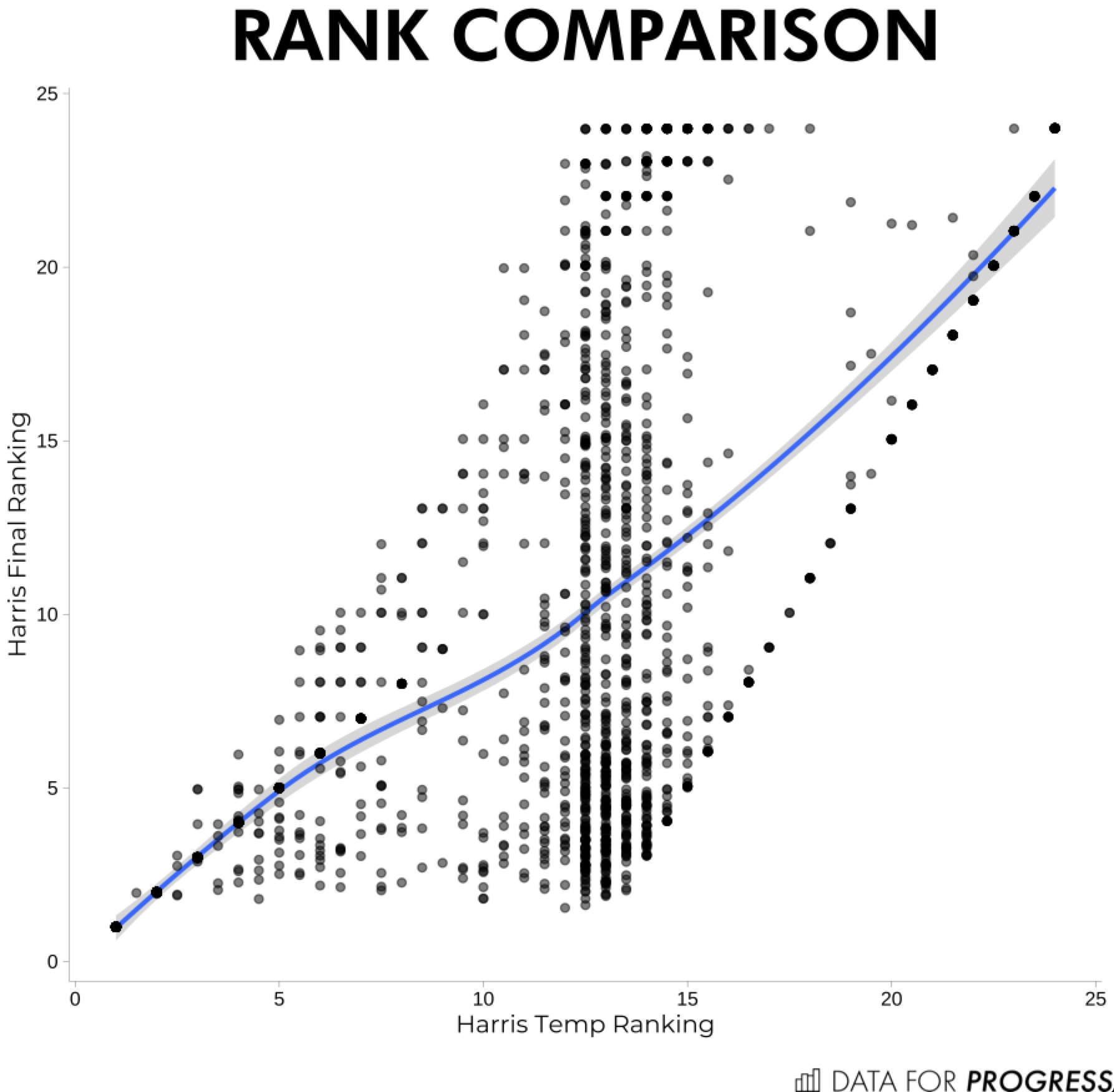
To construct the imputed ranks, I built support models for each of the then 24 candidates. In order to avoid the scores from becoming overly correlated with one another, I omitted support for other candidates as potential predictors. I then ran a combination of gradient boosted trees and lasso regression to choose the remaining questions for each candidate. Moreover, I trained the models to minimize weighted root mean square error as I wanted the predicted values to minimize both bias and variance compared to the original ranks.
The (Lack of) Lanes
Having constructed the ranks we can answer, which candidate supporters are most similar, and which are least similar? For example, we know ranked support for Warren and Harris is correlated -- consistent with other surveys that have found Harris and Warren leading as the others’ second choices. We also know that support for Biden is largely uncorrelated with other candidates (except for perhaps Delaney), while Sanders support correlates somewhat with Warren and others like De Blasio. More fully we can look at the ten candidates who qualified for the September debates, and see how their support is correlated:
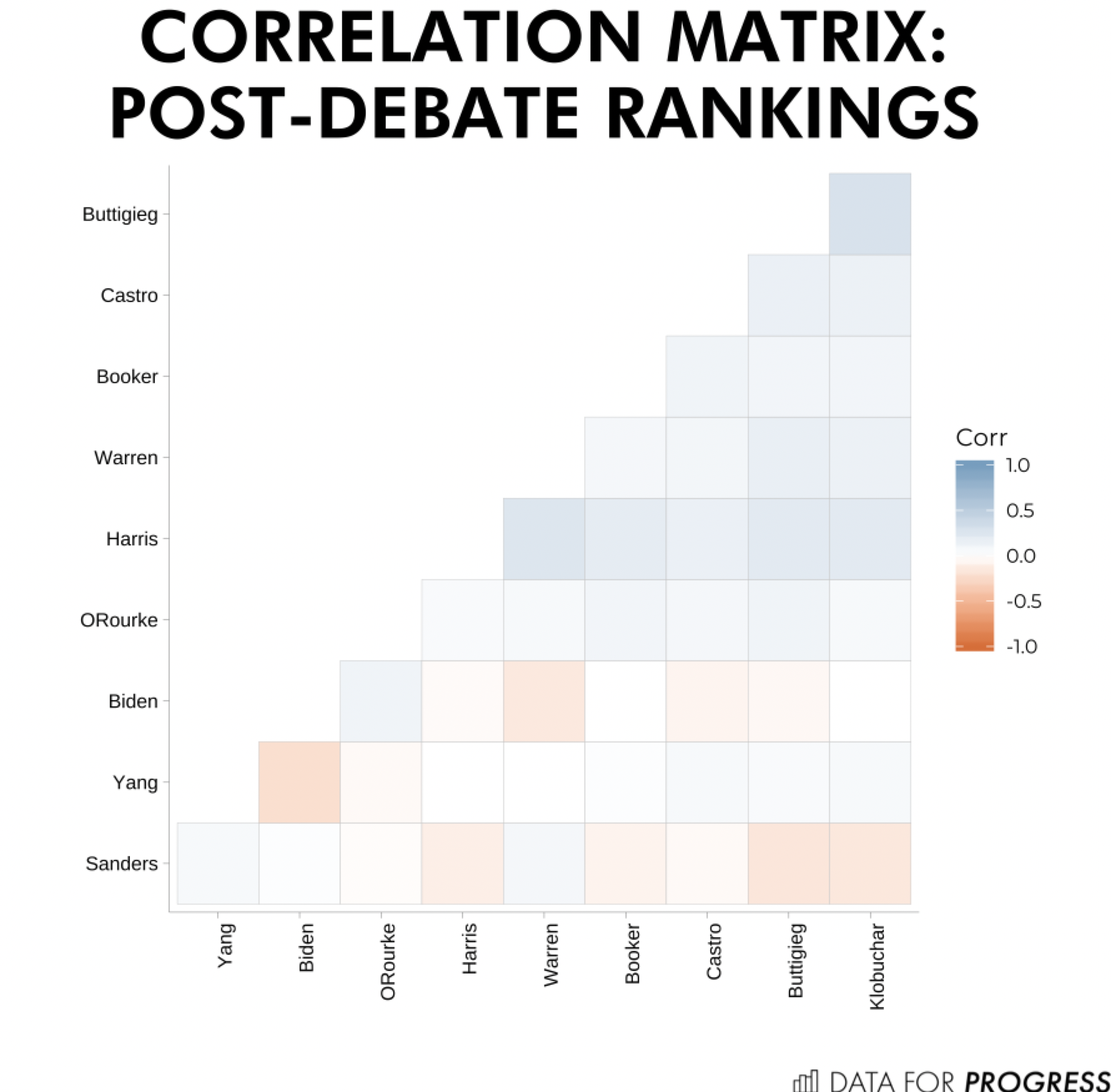
While it’s possible to see potential groupings of candidates, it’s clear that these correlations are not as strong or as clustered together as one would expect if candidate support were strongly defined by being in a certain “lane”. For example while support for Sanders is correlated with Warren, support for Warren is notably more correlated with Harris than Sanders. Bolstering the lack of evidence for support lanes, when I attempt more technical methods like principal components analysis (PCA), I find no component explaining more than a third of the variation in ranked support.
Predicting Support
If support for candidates can only be loosely grouped together, then what does predict support? After constructing these rankings, I extracted the importance of each predictor from building the support models described above. We can use these relative features to see what features were predictive (i.e. not necessarily causal) of candidate support among the full set of survey questions asked. For example, we can find the three most important features for each of the top four polling candidates:
Warren: Hearing a lot about Elizabeth Warren, not placing weight on having a candidate under the age of 50, and placing weight on a candidate who supports increasing taxes on the rich.
Harris: Hearing a lot about Kamala Harris, being middle aged, disagreeing with the idea that most women fail to appreciate fully all that men do for them.
Biden: Being older, not placing weight on having a candidate who supports Medicare For All, and not identifying as progressive or socialist.
Sanders: Having high favorability for the Democratic Socialists of America, placing weight on a candidate who supports Medicare for All, disagreeing that white people in the U.S. have certain advantages because of the color of their skin.
While we can’t determine what causes support for candidates with these models, we can highlight what questions asked of Democratic primary voters predict candidate support in this particular survey.
The Power of “Net Considering”
As building support models is a timely process, it’s natural to ask if we have any measures that well approximate ranked support? Looking at net considering -- the number of people considering that candidate minus the number of people actively not considering that candidate -- appears to be a good proxy.
Using the full ranked data I estimate general support among post-debate respondents by looking at all combinations of “head to head” or pairwise comparisons. This involves taking each pair of candidates, calculating who in that pair has the most support and then repeating for the remaining combinations. Using this definition of pairwise or potential support, I find the nine with the most pairwise support to be: Warren, Harris, Biden, Sanders, Buttigieg, Booker, Castro, O’Rourke, Klobuchar.
When we look at candidate strength by net considering, we come to very similar results about candidate strength as when we look at the full ranks:

Among the top nine candidates, only Sanders and Buttigieg swap places when comparing net consider with ranked support: Warren, Harris, Biden, Buttigieg, Sanders, Booker, Castro, O’Rourke, Klobuchar. As a general rule “considering, but not my first choice” candidates should do relatively better on this metric.
Using net considering as a proxy, we can compare the post and pre debate respondents to see how this measure may have changed over the week:

It’s evident that net considering can provide a more nuanced predictor of general support than merely asking top choice while being less complicated to determine than asking for complete candidate rankings.
Putting It All Together
In a field as large as the Democratic field is now, it is worth exploring varying methods to ask for candidate support. In this post, I specifically looked at estimating full candidate ranks from a survey that asked respondents to rank candidates they are actively considering. At the time of the first debate, I can not find much support that the field is easily divided into lanes or that broad demographics predicts support. Instead, questions like candidate name recognition, age, prioritizing specific policies, and opinions of political groups like the DSA and The #MeToo Movement better predict candidate rankings. Moreover, knowledge of who voters are considering beyond their first choice candidate offers a much more robust understanding of the current state of the Democratic primary.
Zachery Crowell is a political data analyst devoted to promoting progressive policy. Views contained in this post solely represent the author alone, and do not represent the views of any organization.